SPSED Signal Peptide Secretion Efficiency Database
Detail Information for SPSED0005005
| Accession Number | SPSED0005005 |
| Secreted Protein | α-amylase (AmyE) |
| Uniprot Accession Number | - |
| GenBank Accession Number | - |
| Source Organism of the Secreted Protein | Geobacillus stearothermophilus NBRC 12550 | Nucleotide Sequence of the Secreted Protein | Length = 1 nt- |
| Amino Acid Sequence of the Secreted Protein | Length = 1 aa- |
| Expression Host | Corynebacterium glutamicum |
| Source Organism of the Signal Peptide | Corynebacterium glutamicum R |
| Source Gene of the Signal Peptide | CgR0324 |
| Signal Peptide Sequence | Length = 38 aaMVELSTRINPNERRFVVFIAAFLAMILVASGLATPAYA |
| Type | Sec |
| Yield | 95.0722 (mU/ml) |
| Performance (Current Yield / Highest Yield) | 0.33 |
| Charge | 1 |
| Charge (N-Region) | 1 |
| Hydrophobicity | 0.92 |
| Hydrophobicity Plot |
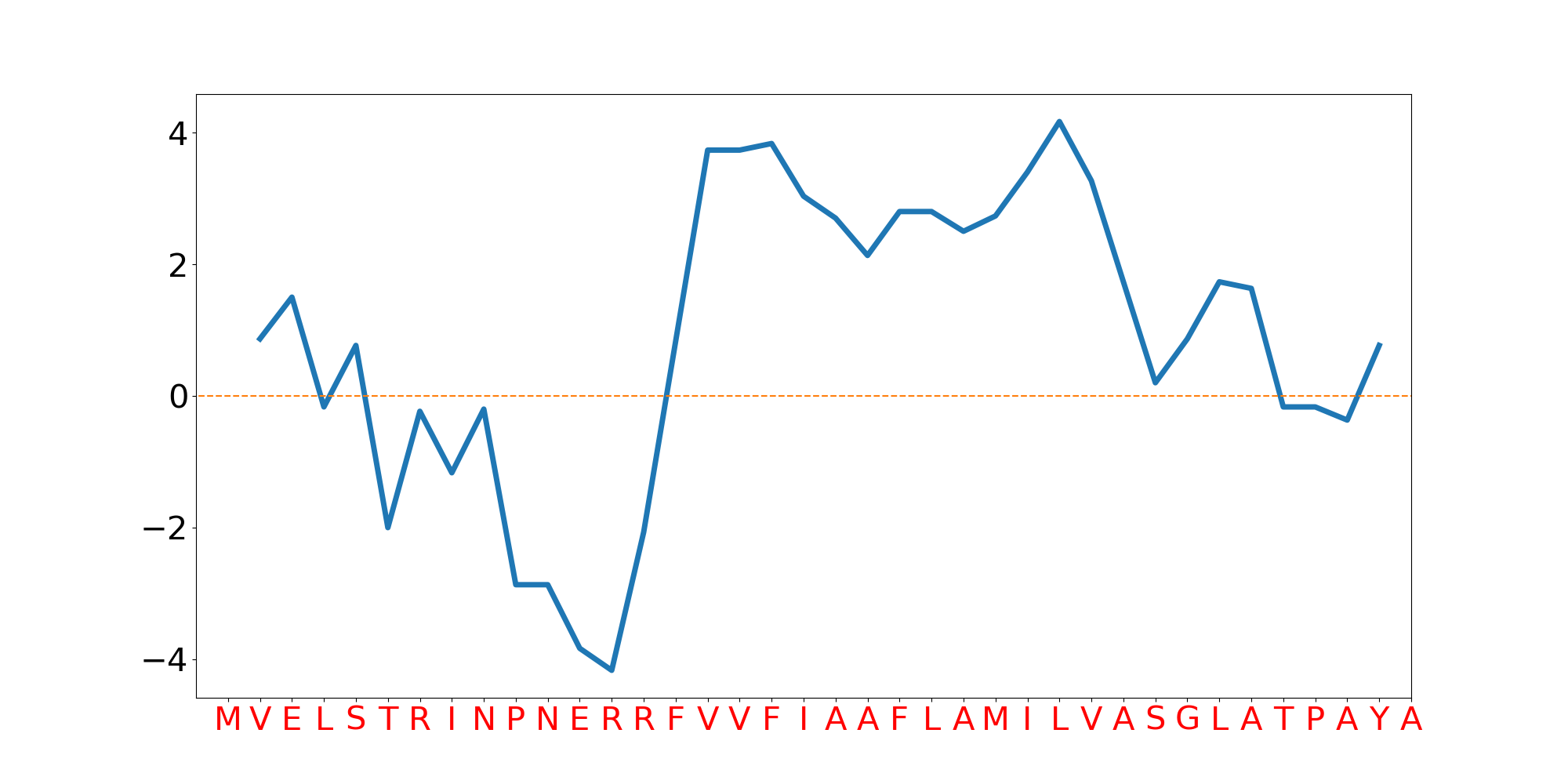
|
| Hydrophobicity (H-region) | 2.69 |
| Signal Peptide Original Protein Sequence | MVELSTRINPNERRFVVFIAAFLAMILVASGLATPAYAQQENAFVVTLPSASSHNGKPVYESGKKLRVEVGYGVMDDGYTGVITVPEQIDPSSIVADLSGNTALESVTPNGDGTITFQFTDPFPAGIQQGLFWLDVELKEFETSGEQELKWEFPDGSTQTIDIVVKSKDDEFKTVSDYENKAISSDPWLEATVENGVVSVDSAAFLGAEIEYRININTAEGGTFKIKDNLDEGLVFIDGSFNATRKTWDSNGMNKEEATVSFPQQSGSSFTESIDLPANSEFVLLYKAQIKDQSAVDAIVDKLQSEYERKREEAGDDEFATIYFSTSFVNSATINDGSEKAASFAINGSESGRVGPEVNGVFSKTSDFAFAEIEDPETNDFEEVDLTYTLKVDLTPYAGFENTSKGLGGNVVIVDTLPSDIKWRDGESDFLVADGMVLTRENSSEPLTAQQFESDEYVGKYYVDGKNLFINIGQDTTTIVSIDVKATITGVNEVWRSGGNSPMEEARYWGPDNTAVLTYPNDKIIRTAKHSFAVMKDGSSGINDPQKFSKTTTNNGPIEITQGEPALIEFKFTIGAGIGDARKSIIVDKIDHDVFDVSEETLAAIKASITGNYHWNYPIDGDTMDVTIDGDGNLVFAPNDQFPKAANWGAEASAPFTETFTFAVTIPTHPLYGKQTLQVENKASYRGSDFETVFDSGTEATATSYGNEMELRKRVYNEDSKTFVSQLRVELNEDGELINDEFIYAVELIPHGQFKNMVLDVEDFLPAEVDFVGFINANDFNSGNLDRVTTDPVTLTNTNAKATYVAGERKVHIGRDVLTSGQTSTLYFKVKLTDFEKDQPIANVIGNAEATIVPSNDYPLNIVKVDTSNEENKITDTNAIFQIKKGDDVVVDNVYVVNGNLVVSGDNGAHKPVAVKEPGEYTIVEVKAPAGFLLTDQEFNVSITEQGVQTPDQVRINNQPGQDVADPVIGTSVAVEGSDVKVLPVSGGTVIDTVTYEGLTVGQKYILEGELFTKAGVATGIKGSREFIAEAADGSVAVAFEISADQIAEYAGEKLVAFESLFELNDDVKSEDPVAEHRDVEDEAQTFTVDELPVADPVIGTSVAVEGSDVKVLPVSGGTVIDTVTYEGLTVGQKYILEGELFTKAGVATGIKGSREFIAEAADGSVAVAFEISADQIAEYAGEKLVAFESLFELNDDVKSEDPVAEHRDVEDEAQTFTVDELPVADPAIGTTAKVTGTTDKVLPLTGGQVIDSVAYKDLQPNTKYVLQGVIQHVATDGTVTSTDVVASTVFTTGDAPAGEFFVSGNAEVKFNIDQATAAEYAGERLVVFEQLWLADDNGNKTGDEPVAVHEDPTDEAQTFYAGEKPDAIPGIGTTAKVTGSADKVLPLTGGEIVDTVAYKDLQPNTEYVLNGEIQHVAEDGTVTSTGVIATATFTTGAAKSGEFYVSGTTTVTFDIDEQTAIKYAGEKLVVFETLYTAGNPETPVASHVDPEDEAQSFTVAPQPEADVVVEKTVTGPKGAQVEADENALFQITATWTDELGRNFSKTFNVVPGKPVSLEGLPTNTEIYLSETGATTDVKNVKWGDVIWTGEGVVDETGTSKGATVTFTGEGPFEIGLENKTSSNGMIIIPIPIPLFPIDGGSSTNPIQPDPTQPDPKESVDPTNPTPSEGSEAGTSPSKDKGAEQPETVKPRTPSEKVGLAQTGANVAWVAGIAILLLLAGAALIVRGRRKDA |
| Signal Peptide Original DNA Sequence | ATGGTTGAATTATCTACCCGCATCAATCCCAATGAGAGGAGGTTCGTTGTTTTCATTGCTGCCTTCCTGGCGATGATTCTGGTCGCCAGTGGACTTGCAACTCCTGCTTATGCCCAACAGGAAAACGCATTTGTTGTCACACTTCCAAGTGCAAGTTCGCACAACGGCAAACCGGTTTATGAATCGGGCAAGAAACTCCGCGTTGAAGTCGGCTATGGTGTTATGGACGACGGCTACACAGGTGTTATCACAGTTCCCGAGCAAATAGATCCGTCAAGCATTGTCGCCGACCTTAGCGGTAATACCGCGCTGGAAAGCGTTACTCCCAACGGTGACGGCACCATTACCTTCCAGTTCACCGATCCATTCCCCGCAGGTATTCAGCAGGGACTTTTCTGGCTTGATGTTGAACTCAAAGAGTTTGAAACCTCCGGCGAGCAGGAACTGAAATGGGAGTTCCCCGACGGAAGCACCCAAACCATTGACATTGTTGTCAAAAGCAAAGACGACGAGTTCAAAACTGTCTCAGATTATGAAAACAAAGCGATCTCCTCGGACCCTTGGCTTGAGGCCACGGTAGAGAATGGAGTCGTCTCAGTAGACTCTGCTGCGTTCCTCGGAGCAGAGATCGAATATCGTATCAACATCAACACTGCTGAAGGTGGCACCTTCAAAATCAAAGACAACCTTGATGAGGGACTTGTCTTTATCGATGGCTCATTCAATGCAACCCGTAAGACATGGGATAGCAATGGAATGAACAAAGAAGAAGCAACGGTGAGTTTTCCGCAGCAGAGCGGTTCTTCATTTACTGAGAGCATTGACCTTCCTGCAAACTCAGAGTTCGTTCTCCTATACAAGGCACAAATTAAAGACCAGAGTGCAGTAGATGCAATCGTCGACAAGCTGCAATCCGAGTATGAACGCAAACGTGAAGAAGCCGGCGACGATGAGTTCGCCACCATTTATTTCTCCACCAGTTTCGTTAACTCCGCCACCATTAATGATGGCAGCGAGAAAGCAGCCTCTTTTGCCATCAACGGCTCAGAATCTGGCCGAGTCGGCCCAGAAGTTAATGGTGTCTTCTCCAAAACCAGTGACTTCGCCTTTGCAGAAATTGAAGATCCAGAGACAAATGACTTCGAGGAAGTAGACCTCACCTACACACTCAAAGTAGATCTCACCCCATACGCAGGATTTGAAAACACTTCGAAAGGCCTTGGCGGCAACGTAGTCATCGTTGACACCCTGCCCTCAGATATTAAATGGCGAGACGGCGAATCAGACTTCCTCGTAGCCGACGGCATGGTTCTGACCCGTGAAAACTCTTCCGAACCTCTAACTGCCCAGCAGTTTGAGTCTGATGAATACGTGGGTAAGTACTACGTTGATGGAAAAAACCTCTTCATCAACATTGGACAAGACACCACCACTATTGTCTCCATTGACGTAAAAGCCACTATCACAGGTGTCAATGAAGTCTGGCGCAGCGGTGGAAACTCACCAATGGAAGAAGCACGCTACTGGGGACCAGATAATACTGCTGTTCTGACCTACCCAAATGACAAGATCATTCGCACTGCCAAGCATTCATTCGCAGTAATGAAGGACGGCTCCAGCGGAATCAATGATCCACAAAAGTTCAGCAAGACCACCACTAACAACGGCCCTATCGAAATTACCCAGGGCGAGCCTGCACTTATTGAGTTCAAGTTCACTATTGGTGCAGGCATCGGTGATGCTCGAAAATCAATAATCGTAGACAAGATTGACCACGATGTTTTTGATGTCAGTGAAGAGACCCTCGCTGCCATCAAGGCTTCCATTACTGGTAACTATCATTGGAACTACCCAATCGATGGCGACACCATGGACGTCACCATTGATGGAGATGGCAACCTTGTTTTCGCCCCGAATGATCAGTTTCCTAAAGCAGCAAACTGGGGAGCCGAGGCTTCTGCACCGTTTACCGAAACGTTTACATTCGCAGTAACAATCCCAACGCACCCGCTTTACGGTAAACAAACACTTCAAGTTGAAAACAAAGCGAGCTACCGCGGATCAGATTTCGAGACCGTTTTTGACTCCGGAACTGAAGCAACAGCAACTTCATACGGCAACGAAATGGAACTGCGCAAACGCGTTTACAACGAAGACAGCAAAACTTTTGTTAGCCAGCTTCGCGTTGAATTGAACGAAGACGGAGAGCTCATCAATGATGAGTTCATCTACGCTGTTGAGCTGATCCCACACGGACAGTTCAAAAACATGGTCTTGGACGTGGAAGACTTCCTTCCCGCTGAAGTTGATTTTGTAGGCTTCATCAACGCCAACGATTTCAACTCCGGGAATCTAGATCGTGTCACCACAGATCCCGTCACTTTGACCAACACAAATGCAAAAGCAACCTATGTGGCAGGGGAGAGGAAAGTTCACATTGGTCGCGATGTCCTAACATCCGGCCAGACCTCTACCCTCTATTTCAAAGTGAAGCTCACAGACTTTGAAAAGGACCAGCCGATCGCCAATGTGATTGGTAATGCAGAAGCAACCATCGTTCCTTCCAATGATTATCCGTTAAACATCGTCAAGGTAGACACCTCAAACGAGGAAAACAAGATTACCGATACCAACGCGATCTTCCAGATCAAAAAGGGTGACGATGTAGTGGTTGACAACGTTTACGTTGTCAACGGAAACCTCGTTGTCTCCGGCGACAACGGTGCACACAAACCAGTTGCTGTTAAAGAACCAGGCGAATACACCATCGTTGAAGTCAAAGCACCAGCTGGATTCCTTCTAACTGACCAAGAATTCAACGTTTCAATCACTGAGCAAGGCGTTCAAACACCTGATCAGGTTCGAATCAACAACCAACCTGGCCAGGACGTAGCTGATCCTGTCATTGGTACTTCGGTGGCAGTTGAGGGCTCTGATGTTAAGGTGTTGCCGGTTTCTGGTGGCACTGTTATCGATACTGTTACCTACGAGGGTTTGACTGTTGGTCAGAAGTACATCCTTGAAGGTGAGTTGTTCACCAAGGCGGGTGTGGCAACCGGTATCAAGGGATCTCGGGAGTTTATTGCTGAGGCCGCTGATGGTTCTGTGGCTGTAGCGTTTGAGATTTCCGCTGATCAGATTGCTGAGTACGCGGGTGAGAAGCTTGTTGCTTTTGAGTCTCTGTTTGAGCTGAATGATGATGTTAAGTCTGAGGATCCTGTTGCTGAGCATAGGGATGTTGAAGATGAGGCACAGACCTTTACCGTGGATGAGCTCCCTGTAGCTGATCCTGTCATTGGTACTTCGGTGGCAGTTGAGGGCTCTGATGTTAAGGTGTTGCCGGTTTCTGGTGGCACTGTTATCGATACTGTTACCTACGAGGGTTTGACTGTTGGTCAGAAGTACATCCTTGAAGGTGAGTTGTTCACCAAGGCGGGTGTGGCAACCGGTATCAAGGGATCTCGGGAGTTTATTGCTGAGGCCGCTGATGGTTCTGTGGCTGTAGCGTTTGAGATTTCCGCTGATCAGATTGCTGAGTACGCGGGTGAGAAGCTTGTTGCTTTTGAGTCTCTGTTTGAGCTGAATGATGATGTTAAGTCTGAGGATCCTGTTGCTGAGCATAGGGATGTTGAAGATGAGGCACAGACCTTTACCGTGGATGAGCTCCCTGTAGCTGATCCTGCAATCGGTACGACTGCTAAGGTCACCGGCACAACCGATAAGGTTCTTCCACTAACCGGCGGTCAAGTTATTGACTCCGTTGCGTACAAGGATCTGCAGCCAAACACCAAGTACGTCCTGCAAGGTGTCATCCAGCATGTTGCTACAGACGGCACTGTCACCTCAACTGATGTAGTTGCTTCCACTGTGTTCACCACTGGGGATGCACCTGCCGGTGAATTCTTCGTGTCAGGAAATGCTGAAGTTAAGTTCAACATTGATCAGGCTACTGCTGCAGAATATGCAGGTGAAAGGCTTGTCGTATTCGAACAGCTGTGGCTTGCTGATGACAACGGTAACAAGACTGGTGATGAACCAGTAGCTGTCCACGAGGACCCTACTGATGAAGCACAGACCTTCTACGCTGGTGAAAAGCCTGACGCAATCCCTGGCATTGGCACCACTGCAAAGGTCACTGGATCTGCAGATAAGGTTCTTCCACTAACTGGCGGCGAAATTGTTGACACCGTTGCGTACAAGGACTTGCAGCCAAACACCGAATATGTTTTGAACGGTGAGATTCAGCATGTTGCTGAAGACGGCACTGTTACCTCCACGGGTGTCATTGCTACCGCTACCTTCACCACTGGTGCAGCGAAGAGCGGCGAGTTCTATGTTTCCGGCACCACCACGGTTACATTCGACATTGACGAGCAGACTGCCATTAAGTACGCAGGTGAGAAGCTTGTTGTCTTTGAAACTCTCTACACTGCTGGAAACCCAGAAACTCCTGTGGCTTCCCACGTAGACCCAGAAGATGAGGCTCAGTCCTTCACTGTTGCGCCACAGCCTGAAGCCGATGTCGTTGTTGAAAAGACTGTCACCGGACCAAAGGGTGCTCAGGTTGAAGCCGATGAAAATGCGCTGTTCCAGATCACCGCAACTTGGACCGATGAACTGGGACGCAATTTCTCTAAGACCTTCAACGTAGTTCCAGGAAAGCCTGTCTCTCTTGAAGGCCTTCCAACCAACACCGAGATTTACTTGTCTGAAACTGGTGCCACAACTGACGTCAAGAACGTCAAGTGGGGCGACGTAATTTGGACTGGGGAAGGCGTTGTTGATGAAACCGGCACGTCAAAGGGCGCGACTGTCACCTTCACTGGTGAAGGTCCATTCGAAATTGGCCTCGAGAACAAGACCAGCTCCAACGGTATGATCATCATCCCAATTCCGATCCCGTTGTTCCCAATTGATGGTGGTTCGTCGACCAACCCAATTCAGCCTGACCCAACTCAGCCAGATCCAAAGGAATCGGTTGACCCAACCAACCCGACTCCTTCGGAAGGATCCGAGGCAGGAACCTCACCAAGCAAGGACAAAGGAGCAGAGCAGCCTGAAACTGTGAAGCCCCGTACTCCTTCTGAAAAGGTTGGACTTGCTCAGACTGGAGCAAACGTAGCGTGGGTTGCAGGAATTGCAATTCTGCTTCTGCTTGCAGGTGCTGCTTTAATCGTCCGTGGACGTAGGAAAGACGCTTAA |
| Reference | Watanabe K, Tsuchida Y, Okibe N, et al. Scanning the Corynebacterium glutamicum R genome for high-efficiency secretion signal sequences[J]. Microbiology-Sgm, 2009, 155: 741-750. [PubMed] |
| Miscellaneous | - |